혼공머신5-2-1
교차검증과 그리드 서치
1. 검증 세트
검증 세트는 하이퍼파라미터 튜닝을 위해 훈련 세트에서 분리한 데이터 세트입니다. 모델의 성능을 평가할 때, 테스트 세트를 사용하지 않도록 합니다.
import pandas as pd
# 데이터 불러오기 및 전처리
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
# 훈련 세트와 테스트 세트로 분리
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42)
# 훈련 세트에서 다시 검증 세트로 분리
sub_input, val_input, sub_target, val_target = train_test_split(
train_input, train_target, test_size=0.2, random_state=42)
print(sub_input.shape, val_input.shape)
위 코드에서 데이터를 불러와 훈련 세트와 테스트 세트로 나눈 후, 다시 훈련 세트를 서브 세트와 검증 세트로 분리합니다.
2. 교차 검증
교차 검증은 훈련 세트를 여러 폴드로 나누어, 각 폴드를 번갈아 가며 검증 세트로 사용하고 나머지 폴드를 훈련 세트로 사용하는 방법입니다.
교차검증 방법
-
데이터를 K개의 폴드로 나눕니다.
-
각 폴드를 번갈아 가며 검증 세트로 사용하고 나머지 폴드를 훈련 세트로 사용하여 모델을 훈련하고 평가합니다.
-
모든 폴드에 대해 검증 점수를 얻고, 이를 평균하여 최종 성능을 평가합니다.
아래는 5-폴드 교차 검증의 예시 그림입니다.
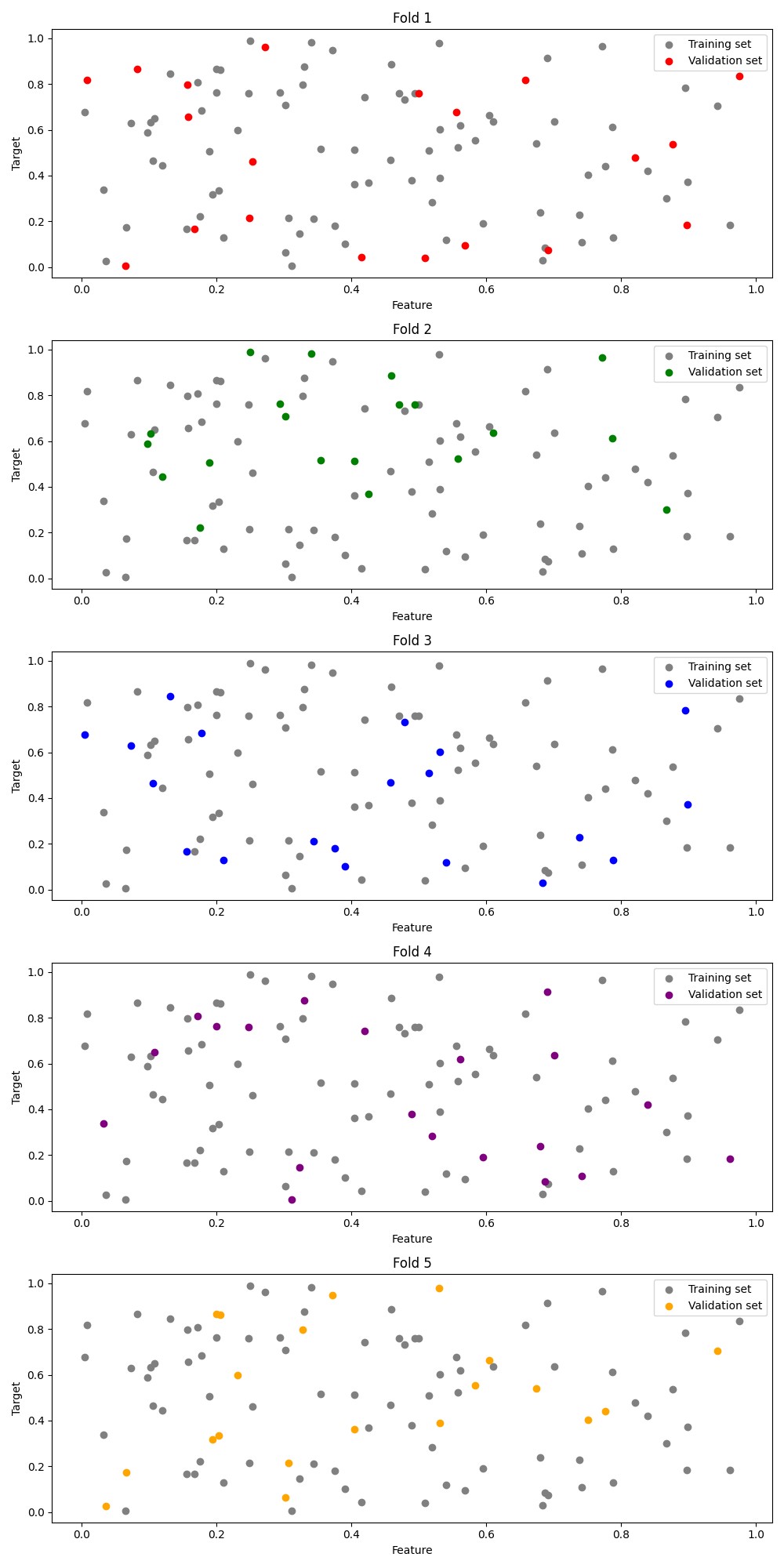
Fold 1: 첫 번째 폴드를 검증 세트로 사용하고, 나머지 폴드를 훈련 세트로 사용합니다.
Fold 2: 두 번째 폴드를 검증 세트로 사용하고, 나머지 폴드를 훈련 세트로 사용합니다.
Fold 3: 세 번째 폴드를 검증 세트로 사용하고, 나머지 폴드를 훈련 세트로 사용합니다.
Fold 4: 네 번째 폴드를 검증 세트로 사용하고, 나머지 폴드를 훈련 세트로 사용합니다.
Fold 5: 다섯 번째 폴드를 검증 세트로 사용하고, 나머지 폴드를 훈련 세트로 사용합니다.
교차 검증을 통한 모델 평가 과정
- 데이터 분할: 전체 데이터를 K개의 폴드로 나눕니다.
- 모델 훈련 및 검증:
- 각 폴드에 대해 모델을 훈련하고 검증합니다.
- 훈련 세트는 (K-1)개의 폴드로 구성되고, 검증 세트는 1개의 폴드로 구성됩니다.
- 평균 검증 점수 계산: 각 폴드에서 얻은 검증 점수를 평균하여 최종 성능을 평가합니다.
from sklearn.tree import DecisionTreeClassifier
# 기본 의사결정나무 모델 훈련 및 평가
dt = DecisionTreeClassifier(random_state=42)
dt.fit(sub_input, sub_target)
print(dt.score(sub_input, sub_target))
print(dt.score(val_input, val_target))
# 교차 검증
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
import numpy as np
print(np.mean(scores['test_score']))
이 코드는 기본 의사결정나무 모델을 훈련하고 검증 세트를 사용해 성능을 평가합니다. 이어서 cross_validate 함수를 사용해 교차 검증을 수행하고, 각 폴드의 성능을 출력합니다.
from sklearn.model_selection import StratifiedKFold
# StratifiedKFold를 사용한 교차 검증
scores = cross_validate(dt, train_input, train_target, cv=StratifiedKFold())
print(np.mean(scores['test_score']))
# 10-폴드 교차 검증
splitter = StratifiedKFold(n_splits=10, shuffle=True, random_state=42)
scores = cross_validate(dt, train_input, train_target, cv=splitter)
print(np.mean(scores['test_score']))
여기서는 StratifiedKFold를 사용해 계층적 폴드를 생성하고 교차 검증을 수행합니다. 10-폴드 교차 검증을 통해 모델의 성능을 평가합니다.
3. 하이퍼파라미터 튜닝
하이퍼파라미터 튜닝은 모델의 성능을 최적화하기 위해 필요한 단계입니다. 이를 위해 그리드 서치와 랜덤 서치를 사용합니다.
그리드 서치
from sklearn.model_selection import GridSearchCV
# 그리드 서치를 위한 하이퍼파라미터 설정
params = {'min_impurity_decrease': [0.0001, 0.0002, 0.0003, 0.0004, 0.0005]}
# 그리드 서치 수행
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
# 최적의 모델 및 하이퍼파라미터
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
print(gs.best_params_)
print(gs.cv_results_['mean_test_score'])
best_index = np.argmax(gs.cv_results_['mean_test_score'])
print(gs.cv_results_['params'][best_index])
이 코드는 GridSearchCV를 사용해 다양한 하이퍼파라미터 조합을 평가하고, 최적의 하이퍼파라미터를 찾습니다.
# 확장된 하이퍼파라미터 그리드 설정
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split': range(2, 100, 10)
}
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))
이 코드는 더 넓은 범위의 하이퍼파라미터를 탐색하여 최적의 조합을 찾습니다.
랜덤 서치
from scipy.stats import uniform, randint
# 랜덤 서치를 위한 하이퍼파라미터 분포 설정
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25)
}
from sklearn.model_selection import RandomizedSearchCV
# 랜덤 서치 수행
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params,
n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
print(gs.best_params_)
print(np.max(gs.cv_results_['mean_test_score']))
dt = gs.best_estimator_
print(dt.score(test_input, test_target))
여기서는 RandomizedSearchCV를 사용해 랜덤한 하이퍼파라미터 조합을 평가하고 최적의 모델을 찾습니다.
문제 해결 과정 - 최적의 모델을 위한 하이퍼파라미터 튜닝
위의 과정을 통해 최적의 모델을 찾기 위한 하이퍼파라미터 튜닝 과정을 정리할 수 있습니다.
- 데이터 준비: 데이터를 훈련 세트와 테스트 세트로 나눕니다.
- 모델 선택: 사용할 모델을 선택합니다. (예: 의사결정나무)
- 교차 검증 설정: 교차 검증을 위한 폴드 수를 설정합니다.
- 하이퍼파라미터 탐색: 그리드 서치 또는 랜덤 서치를 사용하여 최적의 하이퍼파라미터를 찾습니다.
- 최종 모델 훈련: 찾은 최적의 하이퍼파라미터로 전체 훈련 세트를 사용해 최종 모델을 훈련합니다.
- 모델 평가: 테스트 세트를 사용해 최종 모델의 성능을 평가합니다.
이와 같은 과정을 통해 모델의 예측 성능을 최대화할 수 있습니다.
댓글남기기